
About me
Hi👋! My name is Xunhao Lai (赖勋豪). I am a Master’s student at the School of Intelligence Science and Technology at Peking University. Before that, I was an undergraduate student at Yuan Pei College, Peking University.
My research focuses on natural language processing and large language models. Specifically, I concentrate on long context models, exploring innovative and efficient attention mechanisms, as well as optimizing the efficiency of model training and inference.
Publications
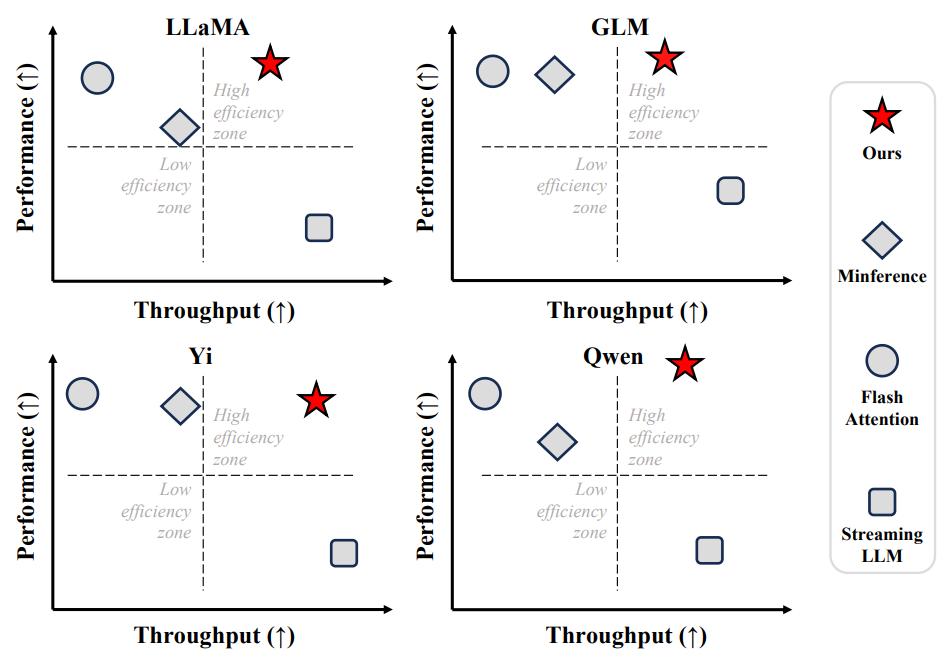
[ICLR 2025 Oral] FlexPrefill: A Context-Aware Sparse Attention Mechanism for Efficient Long-Sequence Inference
Xunhao Lai, Jianqiao Lu, Yao Luo, Yiyuan Ma, Xun Zhou
![]()
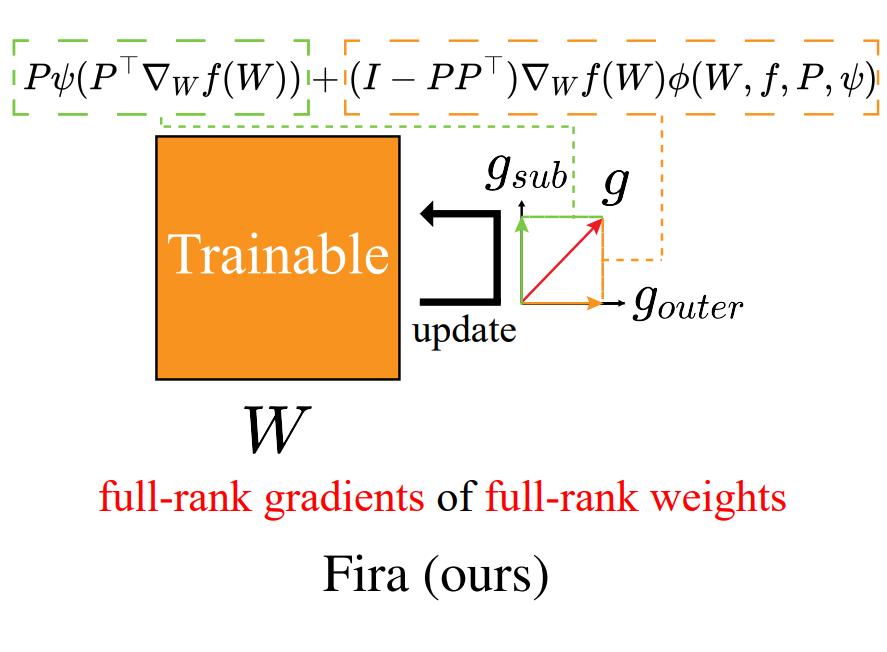
Fira: Can We Achieve Full-rank Training of LLMs Under Low-rank Constraint?
Xi Chen, Kaituo Feng, Changsheng Li, Xunhao Lai, Xiangyu Yue, Ye Yuan, Guoren Wang
![]()
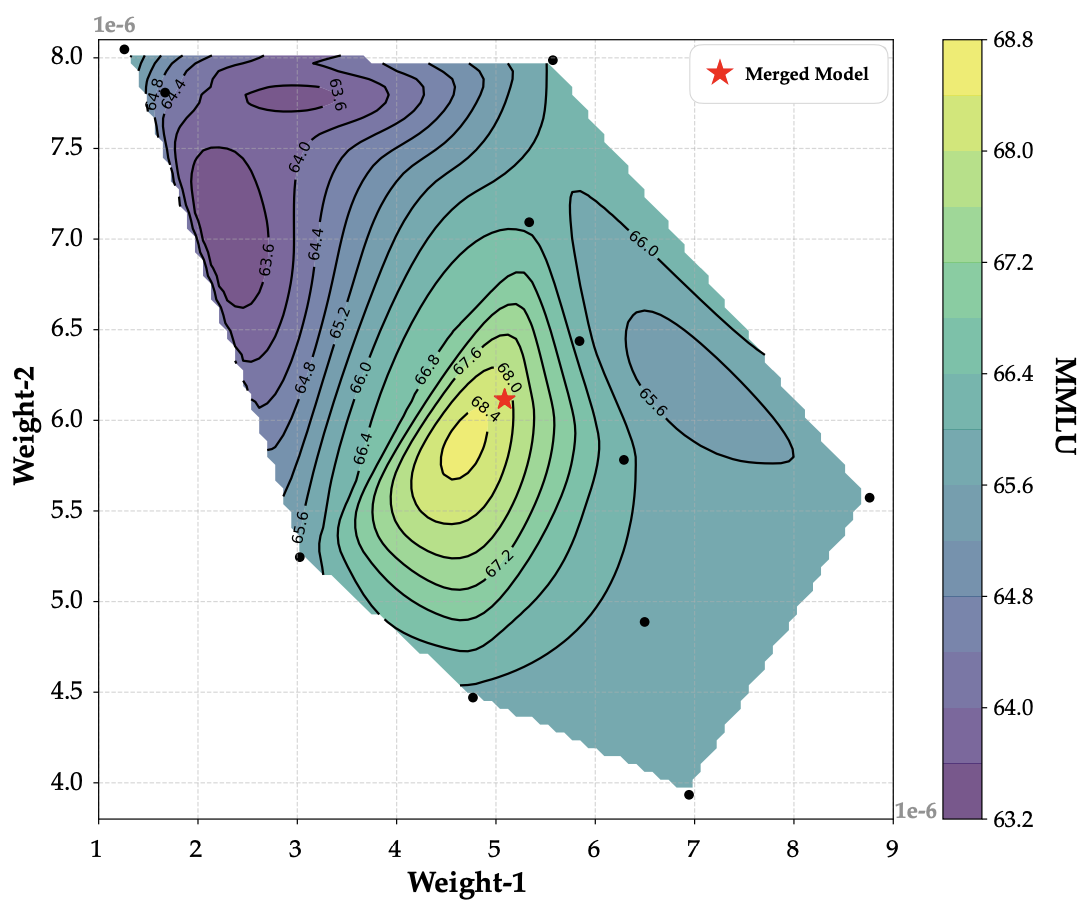
Model Merging in Pre-training of Large Language Models
Yunshui Li, Yiyuan Ma, Shen Yan, Chaoyi Zhang, Jing Liu, Jianqiao Lu, Ziwen Xu, Mengzhao Chen, Minrui Wang, Shiyi Zhan, Jin Ma, Xunhao Lai, Deyi Liu, Yao Luo, Xingyan Bin, Hongbin Ren, Mingji Han, Wenhao Hao, Bairen Yi, LingJun Liu, Bole Ma, Xiaoying Jia, Xun Zhou, Siyuan Qiao, Liang Xiang, Yonghui Wu
![]()
Open-Source Projects
native-sparse-attention-triton
Implemented the Deepseek Native Sparse Attention kernel using Triton, providing flexible and efficient sparse attention training code.
FlexPrefill
Implemented the FlexPrefill long-text inference acceleration algorithm, offering a flexible and efficient acceleration solution for long context LLMs.
ring-sliding-window-attention
Implemented the Ring Attention algorithm for Sliding Window Attention, enabling context-parallel training for long sequences.
Contact
E-mail: laixunhao@pku.edu.cn
Address: Peking University, Beijing, China