
Fira: Can We Achieve Full-rank Training of LLMs Under Low-rank Constraint?
Published in arxiv, 2024
Abstract
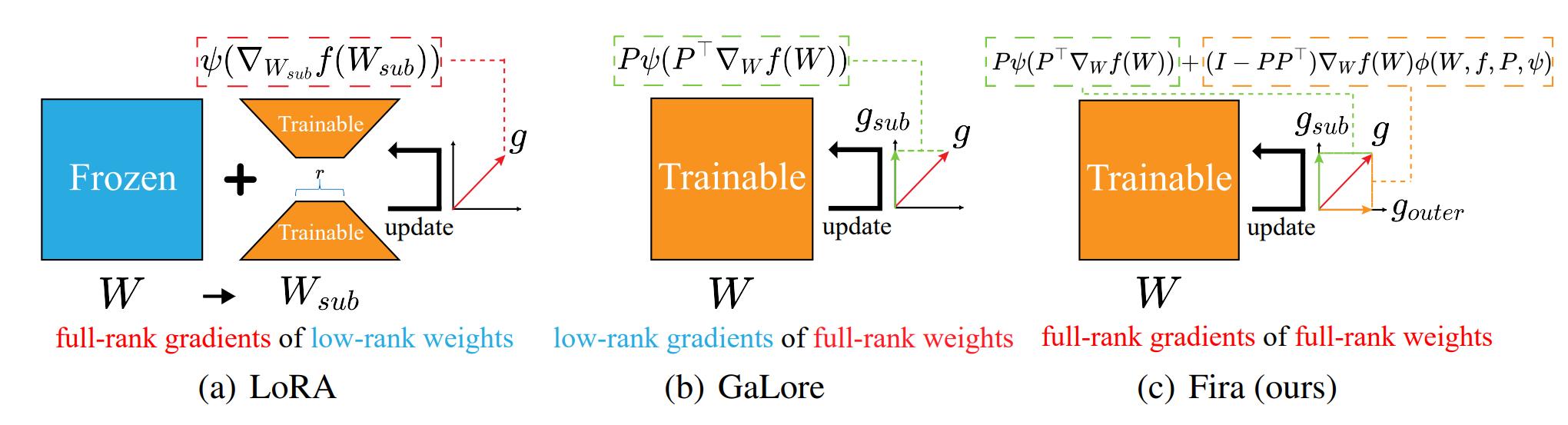
Low-rank training has emerged as a promising approach for reducing memory usage in training Large Language Models (LLMs). Previous methods either rely on decomposing weight matrices (e.g., LoRA), or seek to decompose gradient matrices (e.g., GaLore) to ensure reduced memory consumption. However, both of them constrain the training in a low-rank subspace, thus inevitably leading to sub-optimal performance. To resolve this, we propose a new plug-and-play training framework for LLMs called Fira, as the first attempt to consistently preserve the low-rank constraint for memory efficiency, while achieving full-rank training (i.e., training with full-rank gradients of full-rank weights) to avoid inferior outcomes. First, we observe an interesting phenomenon during LLM training: the scaling impact of adaptive optimizers (e.g., Adam) on the gradient norm remains similar from low-rank to full-rank training. In light of this, we propose a \textit{norm-based scaling} method, which utilizes the scaling impact of low-rank optimizers as substitutes for that of original full-rank optimizers to achieve this goal. Moreover, we find that there are potential loss spikes during training. To address this, we further put forward a norm-growth limiter to smooth the gradient. Extensive experiments on the pre-training and fine-tuning of LLMs show that Fira outperforms both LoRA and GaLore. Notably, for pre-training LLaMA 7B, our Fira uses 8× smaller memory of optimizer states than Galore, yet outperforms it by a large margin.
Download
https://arxiv.org/abs/2410.01623
Code
https://github.com/xichen-fy/Fira
Cite
@article{chen2024fira,
title={Fira: Can We Achieve Full-rank Training of LLMs Under Low-rank Constraint?},
author={Chen, Xi and Feng, Kaituo and Li, Changsheng and Lai, Xunhao and Yue, Xiangyu and Yuan, Ye and Wang, Guoren},
journal={arXiv preprint arXiv:2410.01623},
year={2024}
}